Development
·
8
min read
Python: Guide to structured concurrency

Jan Plesnik

Updated 07-11-2025
We've refreshed this article to reflect modern Python concurrency. While this post once focused on third-party libraries to achieve structured concurrency, the standard library has since adopted these concepts. This update highlights the built-in asyncio.TaskGroup, ensuring our examples reflect the standard way to write resilient concurrent code today.
With the adoption of async-await syntax, modern Python has seen an emergence of coroutine-based asynchronous programming. Frameworks such as the standard library asyncio, Trio, and Dave Beazley's Curio provide event loop implementations and high-level APIs for running coroutines, spawning tasks, and synchronizing between them. Nowadays, many see async Python as the de facto standard approach to writing high-performance network-bound code, such as web servers and database interface libraries. This includes us at Applifting, and since sharing know-how is part of our culture, we are always eager to talk about our experience and practices. In this article, we will discuss the addition of task groups to Python’s asyncio and how they help us write resilient and maintainable concurrent code at scale.
Signull case study
At Applifting, we have chosen Python to develop the backend for Signull, a cryptocurrency market analysis tool for power traders. The project faced a number of technical challenges. In the initial phases, the product team was navigating the uncharted and ever-changing crypto domain and looking to shape an MVP for user validation. Developers needed to make swift deliveries and continuously iterate on new ideas, making it difficult to lay a solid architectural foundation. We were experimenting with various data sources, designing and deprecating worker services on a weekly basis, and looking for ways to ingest live price data for tens of thousands of instruments with minimal latency. The network-bound nature of most technical problems made Python an attractive choice; the concurrency model adopted by asyncio fit the bill nicely.
Signull’s data ingress operates at the scale of hundreds of HTTP requests per second, all the while retrying failed requests, respecting variable rate limits, and synchronizing responses with data fed over not-always-reliable websocket connections. Some workers operate in multiple replicas to facilitate the rate of ingestion, depending on Redis and RabbitMQ for synchronization. As the system scaled, we realized that the product's success will depend on sound usage of synchronization mechanisms, re-entrancy, and resilience in the face of network issues and unreliable data providers.
We learned many valuable lessons on this journey. One of them is that concurrency at scale desperately needs—yet often lacks—strict and enforceable structure. Before we dive into the details of what this means in practice, let us recap on Python’s concurrency model.
Coroutine-based concurrency
Coroutines can be understood as an alternative concurrency model to shared-state threading (whether system native or not). In the Python community, the threading module is often dismissed as inadequate or even pointless due to the notorious CPython GIL (although there are valid reasons for its existence). GIL aside, however, multithreading as an implementation-agnostic concept is still burdened by a number of issues. In a system with preemptive scheduling and arbitrary concurrent execution, local reasoning becomes significantly more difficult and error-prone. Developers must introduce mutex and synchronization mechanisms to protect against race conditions, but the correctness of such mitigations is difficult to verify and must be considered whenever making adjustments to the code or even calling it.
You have to have a level of vigilance bordering on paranoia just to make sure that your conventions around where state can be manipulated and by whom are honoured, because when such an interaction causes a bug it’s nearly impossible to tell where it came from.
Coroutines differ from threads in that they implement cooperative multitasking—they must yield control or suspend explicitly (e.g. via a yield or await statement). This means that the programmer is always aware of a potential context switch and is able to arrange a graceful and safe suspension. Glyph compares this sort of statement to a relief valve: a single clearly marked point where we have to consider the implications of a potential transfer of control. As such, coroutines can be thought of as a semantic improvement over threads.
The problem of runaway tasks
Despite the convenience of coroutine-based concurrency, Python's asyncio module has long lacked an intuitive and convenient way to manage groups of concurrently running tasks. The current API revolves around create_task, which returns a task handle to the user. The user is then responsible for keeping references to running tasks, collecting return values, and handling safe cancellation in case of errors. This is notoriously difficult and prone to errors. The lack of correct task management leads to runaway tasks, which never get awaited by the parent or checked for exceptions. As a result, the program can easily end up in an invalid state while failing to emit any kind of error or warning.
Consider the following code:
The parent task spawns two child tasks, A and B, and lets them run in the background. Eventually, it awaits the completion of A. Once A is done, it either produces a return value or propagates an exception into the call stack. However, B is never awaited, which is not strictly wrong, but it exposes us to the following scenarios:
The task dies without our knowledge. Seemingly unrelated code may deadlock or start misbehaving, as it assumes that the task is running in the background.
We expect the task to have ended, but a bug in its termination logic makes it run silently in the background, causing unexpected behavior elsewhere.
Both situations are nightmares to debug. Once the example function exits, B becomes orphaned—we lose our reference to the task and are no longer able to manage its lifetime.
The control flow can be illustrated as such:

While task A eventually rejoins the parent, task B runs away, and we lose control over it. It is possible to make an analogy to an orphan thread. The issue at hand is that asyncio not only doesn't help us prevent such behaviors, it almost hints at them being the correct and safe approach to concurrent computation.
What can be done to alleviate this problem?
Enter nurseries
Let's look at the approach taken by Trio, an alternative async Python framework. In Trio, it is not possible to spawn tasks without first giving them a place to live: a nursery. Nurseries are context managers that expose an interface similar to asyncio.create_task. However, tasks are always owned and managed by the nursery which spawned them, and the nursery context will never exit until all its tasks have completed by producing a return value or raising an exception. When a task fails, the nursery ensures that all concurrently running tasks are properly canceled, giving every task the ability to gracefully clean up. After all tasks are done, the exception is propagated back through the call stack.
Let's look at an example:
Trio ensures that the async with block will not exit until both tasks have completed. Arbitrary computation, including await statements, can be done before, in-between, and after task creation. To aid with this, nurseries also offer a blocking start call, which allows waiting for a task to initialize but not finish. For example, we may want to wait for a consumer task to establish a connection to a message broker before proceeding with a corresponding producer task. Arbitrary nesting is allowed—tasks can open their own nurseries internally, which creates a hierarchical structure with clearly defined parent-child relationships. To retrieve return values from tasks, it is common to use a shared object, such as an async-ready queue or a plain dictionary. In many cases, however, tasks primarily need to pass information between one another, which is commonly achieved by passing a shared queue reference, as seen in the example.
Nurseries serve as explicit branching points, where the lifetime of concurrent tasks begins and eventually ends. One of the advantages of this pattern is that every task has a parent awaiting its completion. This guarantees that exceptions happening in concurrent tasks always have a place to propagate to. The control flow diagram now looks like this:
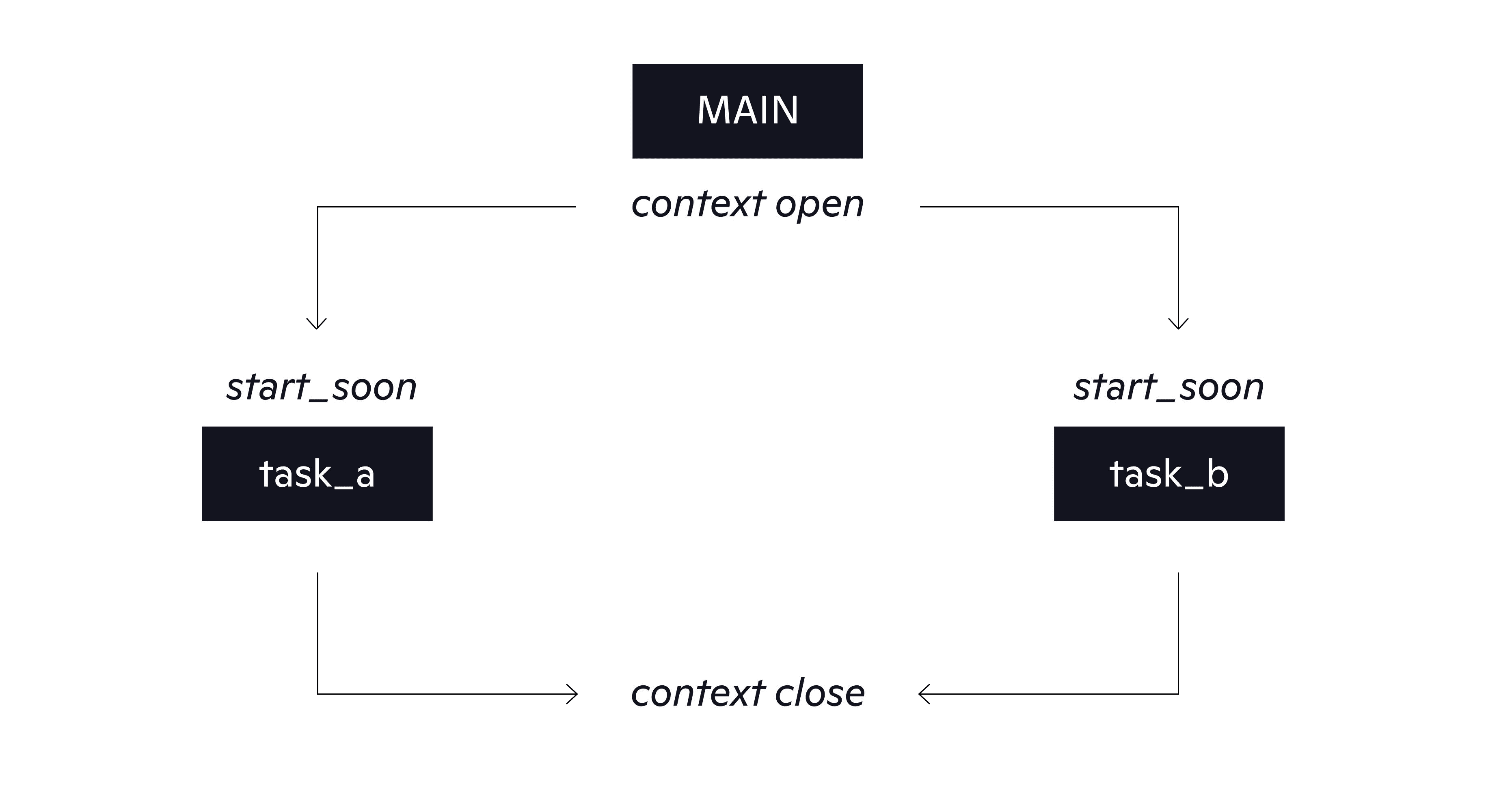
We have previously discussed how coroutines make reasoning about concurrency easier due to explicit suspension points. Similarly, the nursery pattern creates semantic improvement via explicit lifetime representation of async tasks. This relatively new concept is often referred to as structured concurrency and is explained in great detail in Martin Sústrik’s blog post. Surveying other modern languages, we can draw a clear parallel to Kotlin’s coroutine library, which achieves structured concurrency via CoroutineScope. Its purpose is analogous to Trio’s nurseries: to delimit the lifetime of concurrent tasks, ensure that they never leak, and never swallow errors silently. A nursery implementation also exists for Golang, but it is not part of the standard library.
The observed benefits of structured concurrency can be compared to those of the now commonplace structured programming. Enforcing a logical structure on a program’s control flow makes it easier to understand, modify, and verify for correctness.
TaskGroups in asyncio
Prior to Python 3.11, the majority of async libraries—and therefore applications using them—targeted asyncio compatibility. One could rightfully question the practicality of Trio’s nurseries in such an ecosystem, beyond a theoretical proof of concept. Fortunately, the amazing AnyIO project brought structured concurrency to the asyncio world. In AnyIO, nurseries are generalized as task groups, making structured concurrency accessible across different async backends.
With the release of Python 3.11 in October 2022, TaskGroup—following the structured concurrency model popularized by Trio and adopted by AnyIO—became a native part of asyncio. This was enabled by PEP 654, which extends Python’s exception-handling syntax to support exception groups through the except* clause, making them a feature of the language itself. Exception groups provide the foundation that allows task groups to handle and propagate multiple errors from concurrent tasks in a structured way. With this addition, the Python standard library now offers a structured alternative to asyncio.gather, providing a clearer and safer API for concurrent task execution. As CPython core developer Yury Selivanov noted, “this makes Python one of the best-equipped languages for writing concurrent code.” Beyond convenience, the presence of task groups in the standard library encourages better patterns and safer code, not just for experienced developers, but for beginners learning asynchronous programming.
Conclusion
Throughout Python’s long history, we have seen an emergence of various frameworks implementing coroutine-based concurrency. The standard library has provided futures and executors, and eventually asyncio and async-await syntax. Meanwhile, many community projects were developed in parallel, such as StacklessPython, Twisted, Gevent, or Tornado. For a long time, concurrency in Python has been in a fragmented state and lacked a broader consensus on standard tooling and approaches. Given this context, it’s great to see Python’s ecosystem stabilize around asyncio and help pioneer modern concurrency patterns.
Applifting’s Python team can speak from experience. Task groups allowed us to gradually introduce structure to Signull’s heavily concurrent codebase, drastically improving our ability to reason about it. In turn, we started designing and delivering safer and more resilient solutions. This led to a noticeable improvement in our productivity and the availability of our services. We were able to extort annoying heisenbugs, improve our error reporting, and allow services to gracefully recover in unexpected scenarios. It is in the Zen of Python that errors should never pass silently, and task groups finally give us a powerful tool to ensure this principle despite the intricacies of concurrent computation.
Did you get lost? Simply reach out, and our experienced team will be happy to assist you.






